LLM Reference
LLM Reference helps tech leaders quickly find and compare the best AI models and providers for their specific project needs.
Visit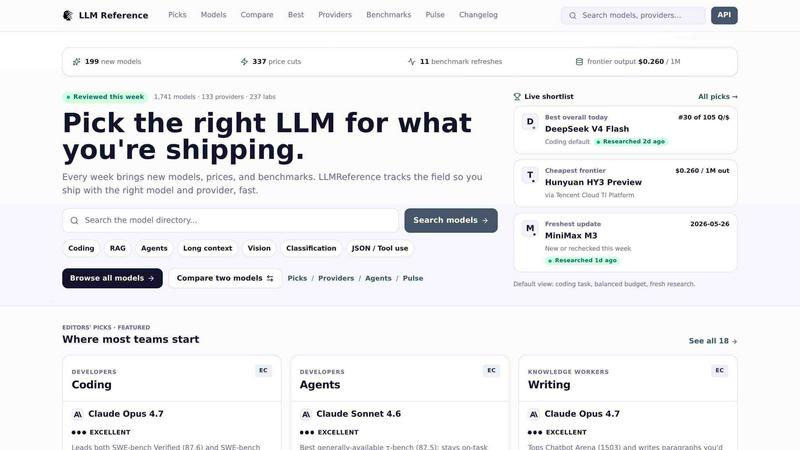
About LLM Reference
LLM Reference is a comprehensive decision-support directory designed specifically for engineers, technical leaders, and AI practitioners who need to select the optimal large language model (LLM) and provider in the rapidly evolving AI landscape. The platform tracks an extensive database of over 1,800 language models from more than 140 providers and 247 research labs, with data refreshed weekly to capture new releases, verified price changes, and benchmark updates. Its core value proposition is eliminating the time wasted hunting through scattered sources, enabling teams to ship with confidence. Whether you are building a coding assistant, an agentic workflow, a writing tool, or a research pipeline, LLM Reference provides a single, trustworthy place to compare models side-by-side. Users can identify the cheapest pricing for frontier output, browse curated editors' picks for specific tasks such as coding, agents, writing, research, image generation, and video creation, and access a Pulse feed that highlights weekly changes including new models, price cuts, and benchmark refreshes. The site is built for fast triage, allowing users to quickly identify the right model for their job, determine the most cost-effective provider, and return to building. It is maintained by the Data Advantage project and updated daily, making it an essential resource for anyone needing to stay current with the exploding LLM ecosystem.
Features of LLM Reference
Comprehensive Model Directory
LLM Reference maintains an exhaustive, searchable directory of over 1,800 language models from more than 140 providers and 247 research labs. Users can search by model name, provider, or task category to quickly locate relevant options. The directory is updated weekly with new releases, ensuring users always have access to the latest frontier models and open-weight alternatives.
Side-by-Side Model Comparison
The platform enables direct comparison of two models across multiple dimensions including performance benchmarks, pricing per million tokens, context window size, and supported capabilities. This feature allows users to evaluate trade-offs between cost and quality, making it easier to select the most appropriate model for specific tasks like coding, agent workflows, or long-context reasoning.
Curated Editors' Picks
LLM Reference features expert-curated recommendations for specific use cases, including coding, agents, writing, research, image generation, and video creation. These picks are based on rigorous evaluation of benchmark scores, real-world performance, and cost efficiency. For example, Claude Fable 5 is the top pick for coding with an 80.3% SWE-bench Pro score, while Veo 3.1 leads for video generation with 30-second clips and native audio.
Pulse Feed and Change Tracking
The Pulse feed provides a weekly summary of market changes, including new model releases, verified price cuts, and benchmark refreshes. Users can see at a glance how many new models were added (e.g., 177 new models in a recent week), how many price reductions occurred, and which benchmarks were updated. This feature keeps professionals informed without information overload.
Use Cases of LLM Reference
Selecting a Coding Assistant Model
Engineering teams building AI-powered coding assistants can use LLM Reference to identify the best model for their needs. The platform highlights top performers like Claude Fable 5 with an 80.3% SWE-bench Pro score and 96% SWE-bench Verified on Vals.ai. Users can compare pricing across providers to find the most cost-effective option for high-volume code generation tasks.
Optimizing Cost for Agentic Workflows
Teams deploying agent-based systems that require frequent API calls can leverage LLM Reference to find the cheapest frontier output. The platform tracks real-time pricing, such as Hunyuan HY3 Preview at $0.260 per million output tokens via Tencent Cloud TI Platform. This allows architects to balance performance with budget constraints for production deployments.
Benchmarking Research Models
Researchers and data scientists can use LLM Reference to track the latest benchmark scores across major evaluation suites. The platform aggregates data from multiple benchmarks including SWE-bench, Chatbot Arena, GDPval-AA, and OSWorld-Verified. This centralized view saves hours of manual research when comparing model capabilities for academic or applied research projects.
Identifying Multimodal Capabilities
Creatives and product teams exploring image generation or video creation can use LLM Reference to find the best models for their specific medium. The platform provides editors' picks for image generation (e.g., FLUX.2 Dev for photorealistic output) and video generation (e.g., Veo 3.1 for 30-second clips with native audio), along with comparisons of pricing and output quality.
Frequently Asked Questions
How often is the model directory updated?
The model directory is updated weekly with new releases, verified price changes, and benchmark refreshes. The platform also features a daily update cycle to capture the most recent changes. Users can check the Pulse feed and Changelog for a detailed breakdown of what changed each week, including counts of new models, price cuts, and benchmark updates.
What criteria are used for editors' picks?
Editors' picks are based on a combination of benchmark performance, real-world task suitability, cost efficiency, and expert evaluation. For example, coding picks prioritize SWE-bench scores and verified accuracy on engineering tasks, while writing picks consider Chatbot Arena ELO ratings and subjective quality assessments. Each pick includes a rationale explaining why the model was selected for that specific use case.
Can I compare models from different providers?
Yes, LLM Reference is designed specifically for cross-provider comparisons. Users can select any two models from the directory and view side-by-side comparisons of their pricing, benchmark scores, context windows, and supported features. The platform also includes a "Best of" section that ranks models across providers for specific tasks like coding, agents, and long-context reasoning.
How does the platform verify pricing information?
Pricing information is verified directly from provider sources and updated weekly. The platform tracks both standard and discounted pricing tiers, and any price cuts are highlighted in the Pulse feed. Users can see the exact cost per million input and output tokens for each model-provider combination, enabling accurate cost projections for production deployments.
Similar to LLM Reference

EchoLeads AI
EchoLeads AI automates outbound cold calling and inbound lead qualification with natural voice agents to schedule appointments and close sales.
BlueHumanizer
BlueHumanizer transforms AI-generated text into clear, natural writing with one click, preserving meaning while improving flow and readability.
Serro AI
Serro AI is a coordination layer that automatically captures and maintains live program memory across your tools to keep human-agent teams aligned.
Sitp GPT
Sitp GPT is an AI-powered SaaS toolkit with 60+ tools for sitemaps, SEO, copy, conversions, and billing.
Plant Identify
Identify any plant, flower, or tree instantly with a photo and get tailored care tips and disease diagnosis.